The most useful word I’ve added to my prompts this year is prove.
When you ask a coding agent to “implement feature X and make the tests pass,” you get exactly what you asked for: passing tests. Often that means mocked dependencies, stubbed responses, and a green checkmark that proves the agent can write an assertion — not that the feature works. A mock is a mirror: the test passes because you told it what the answer should be.
So I stopped asking for passing tests. I ask the agent to prove the feature works. The verb does real work. “Prove” pushes the model off the happy path of fabricated green and toward evidence: run the thing, hit a real dependency, show me the output.
Gate 1: prove it locally, no mocks
I run a local stack with Tilt — real Postgres, real queues, real services, all spun up on my machine. When I ask Claude to prove a feature, the rule is simple: no mocks for anything Tilt already provides. If the feature writes to the database, prove it by reading the row back. If it publishes an event, prove it by consuming it. If it calls an internal service, call the real one running in the cluster.
This catches the class of bug that mocks hide by construction: a wrong column type, a migration that didn’t run, a serialization mismatch, an off-by-one in a real query. A mocked test stays green through every one of those.
Gate 2: prove it again on staging
Local Tilt is honest about internal dependencies, but it still fakes the outside world. Third-party APIs, production-shaped data, the integrations you can’t run on a laptop — those only exist downstream. So after merge, I ask for the same proof on staging, which is wired to real data and real integrations.
Same verb, harder environment. The local proof says “the logic is correct against real internal services.” The staging proof says “it survives contact with real data and the systems we don’t control.” Plenty of features clear the first gate and fail the second — a payload shape that never showed up in my seed data, a rate limit, an auth quirk in a real integration. That’s the point. The second gate exists precisely to catch what the first one structurally can’t.
Why two and not one
You could argue for staging only. But the local gate is fast and tight — seconds to minutes, full control, runs before review. Staging is slow and shared; do all your proving there and you turn it into a debugging ground with a queue. The two gates split the work by what each is good at: local proves the logic cheaply, staging proves reality once.
Neither gate uses a mock. That’s the whole idea. A mock proves you understood your own assumptions. Real dependencies prove the feature.
Why this works now
None of this is a new idea. Proving a change against real dependencies is just what careful engineers always did by hand — port-forward, open psql, read the row back, check the inbox. The reason it rarely happened on every change is that it’s tedious, and tedium is the first thing that gets cut under a deadline. A mocked green test is one keystroke; chasing an effect through a real queue into a real database is twenty minutes of unglamorous plumbing.
The agent doesn’t get bored and doesn’t cut the corner. It will run the twenty minutes of plumbing on a Tuesday afternoon for a change nobody is watching. That’s the actual shift here: the discipline was always correct, just too expensive in human attention to apply consistently. Moving it onto an agent drops the cost to near zero — so you can afford to do it always, not only before the scary releases.
From a habit to a skill
The two-gate routine worked well enough by hand that we turned it into an actual Claude Code skill — /team-eng:prove — so the discipline no longer depends on remembering to phrase the prompt right. The skill just encodes the rules I’d been applying loosely.
One rule: real or it doesn’t count. Proof means an observed effect produced by the real code under test, with evidence captured this session. A passing assertion, “the logic looks correct,” or an HTTP 200 when the criterion was actually about a downstream row — none of those count.
Simulator vs mock — the distinction the whole thing is built on. A simulator runs the real protocol against a local stand-in for a cloud service: the PubSub emulator, Mailpit for email, local Postgres, Kind for the Kubernetes API. The real code path executes. A mock replaces your code’s collaborator with something that returns a canned answer. Simulators prove; mocks don’t. That one line is what separates Gate 1 from theatre.
It picks the gate for you. From the prompt and the git state — a feature branch with unmerged work, or main after the PR landed — the skill decides whether this is a local (Tilt) or a staging proof, and says which it chose so you can correct it.
Chase the effect to where it lands. The skill refuses to stop at the 200. If the feature writes a row, it reads the row back. If it publishes a message, it confirms the real consumer processed it. If it sends an email, it reads the message out of Mailpit.
It doesn’t quit while a criterion is red. A failing check isn’t a result to report — it’s a bug. The skill root-causes it, fixes it, redeploys into the environment under test, and re-proves end to end, looping until every criterion is green. Staging is special-cased: you can’t hot-patch it, so a fix gets proven locally in Tilt first and the merge stays gated on a human.
It guards against proving stale code. Before a staging proof it checks the deployed image SHA against the merge — if staging hasn’t rolled the change out yet, it waits instead of proving old code and calling it done.
The output is a small evidence table: each criterion, the real action that exercised it, the captured output, PASS or FAIL. Every PASS has to cite output someone actually saw this session. That’s the artifact “prove” produces — not a green checkmark, a paper trail of reality.
The craft you can take with you, skill or not, is writing the criterion as an observable. “The create-widget feature works” can’t be proven — there’s nothing to point a command at. “POST /widgets returns 201 and a widgets row exists with status=active and a widget.created message gets consumed” can: each clause is a command and an output you either see or you don’t. Half the value of “prove” is that the word forces you to phrase what you built in terms of effects you can go observe. The prompt itself is as plain as it sounds:
Prove the BIT-768 change works locally. No mocks — drive the real worker functions against the Tilt Postgres, read the alert rows back, and give me an evidence table.
Here’s the actual report from one real prove run — a local, pre-merge proof of a budget/key-expiry auto-resolve change, driving the real worker functions against a real Postgres with real rows:
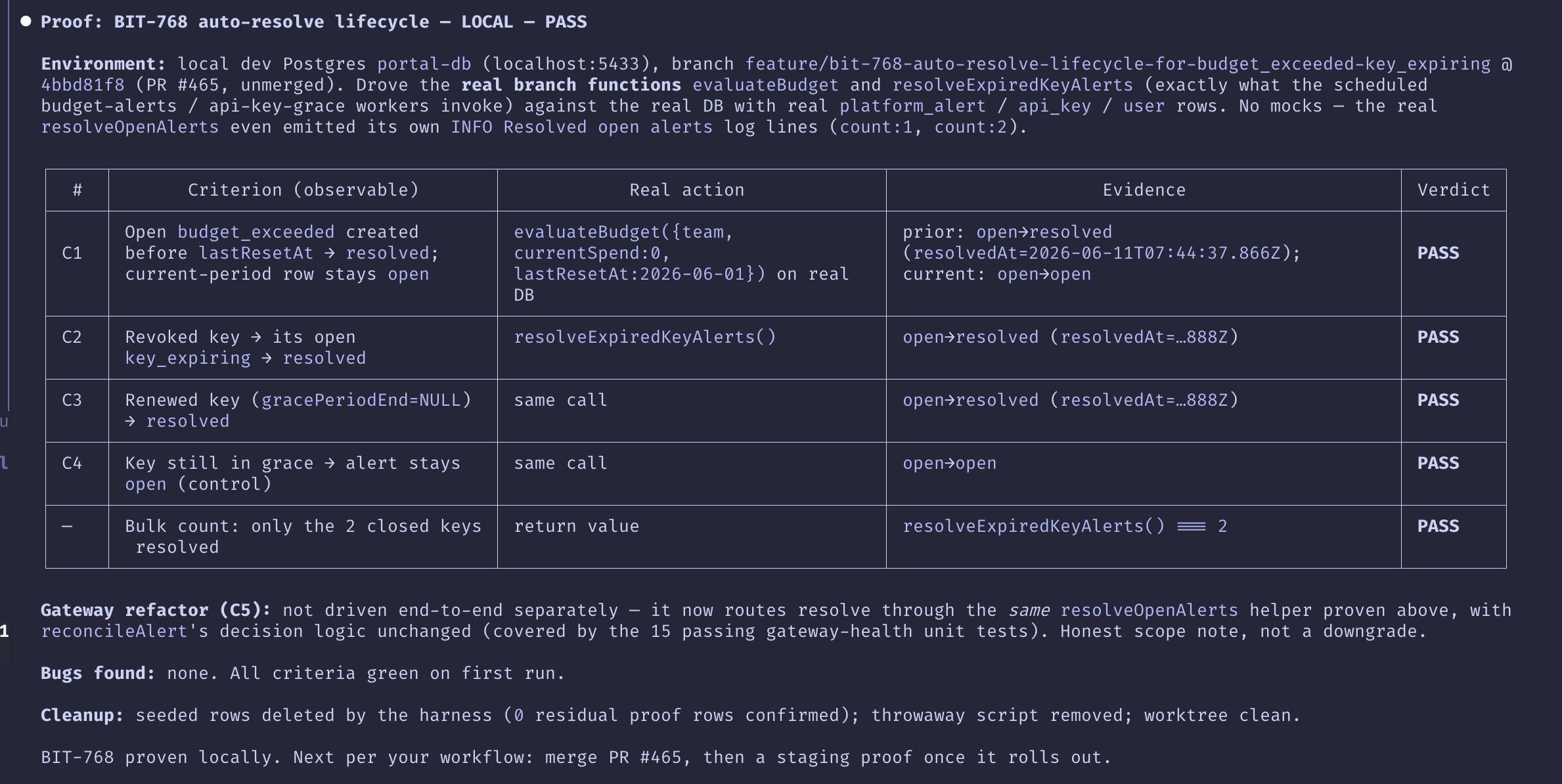
The actual report from one local prove run — the evidence table the skill emits, verbatim.
Note the shape. Every PASS cites a real state transition read back off the real DB — open→resolved with an actual resolvedAt timestamp — not an assertion. C4 is a deliberate control: a row that should not change, proving the function is selective and not just resolving everything. And the last line is the handoff the whole post is about: local gate green, staging gate still to come.
What it doesn’t replace
This isn’t a substitute for your test suite. Unit and integration tests are the fast signal that runs on every commit and guards against regressions forever; a proof is a one-time “I watched the real thing happen” for a specific change. They compose: when proving surfaces a bug, the fix ships with a regression test so the next person doesn’t have to re-prove it by hand. Tests tell you something stopped working; a proof tells you it started.
And you don’t prove everything. Proving costs minutes and tokens, so it earns its keep on the changes where a mock would most plausibly lie: migrations, message consumers, anything touching money, auth, or data you can’t easily reverse. A copy change or a CSS tweak doesn’t need a proof — it needs a glance. Treat it as a scalpel for the changes where “the code looks right” has burned you before, not a blanket policy.
It isn’t perfect. The skill still leans toward confirming the happy path — hand it a criterion and it works hard to show that one criterion passing, which is a milder version of the very bias the method is meant to kill. We see it, and we keep tightening the prompts and the way criteria get gathered to push it toward genuinely adversarial proof — making it hunt for the failure, not just the green. It’s a step toward better results as we see it, and we keep improving it; it’s not the finish line.
It also isn’t Claude-only. We maintain an OpenCode version of the same skill, so the proof discipline travels with us whichever agent we happen to be driving.
Building agent-driven workflows like this? At Bitropy we build the enterprise layer for AI agents — making MCP servers and LLM workloads safe, observable, and cost-efficient at scale. I also consult independently on agentic coding adoption and AI transformation — see dwornikowski.com.
A note on style: English isn’t my first language. I draft these posts myself and use an AI assistant for copy-editing. The ideas and decisions are mine.